What it does
At 06:00 every morning, Daglig Vejr fetches weather and pollen data, runs it through a classification layer calibrated to my personal allergy profile, and sends me an HTML email with concrete recommendations: what to wear, whether to put on sunscreen, whether to take a hay fever pill, and whether to grab an umbrella on the way out.
I have a class 6 grass pollen allergy and I run outside most mornings. Getting those four things wrong on the same day is genuinely unpleasant. The project started as a practical fix for that, and grew into something that demonstrates end-to-end production thinking: real data, a daily output I actually use, a feedback loop, and a machine learning layer that improves over time.
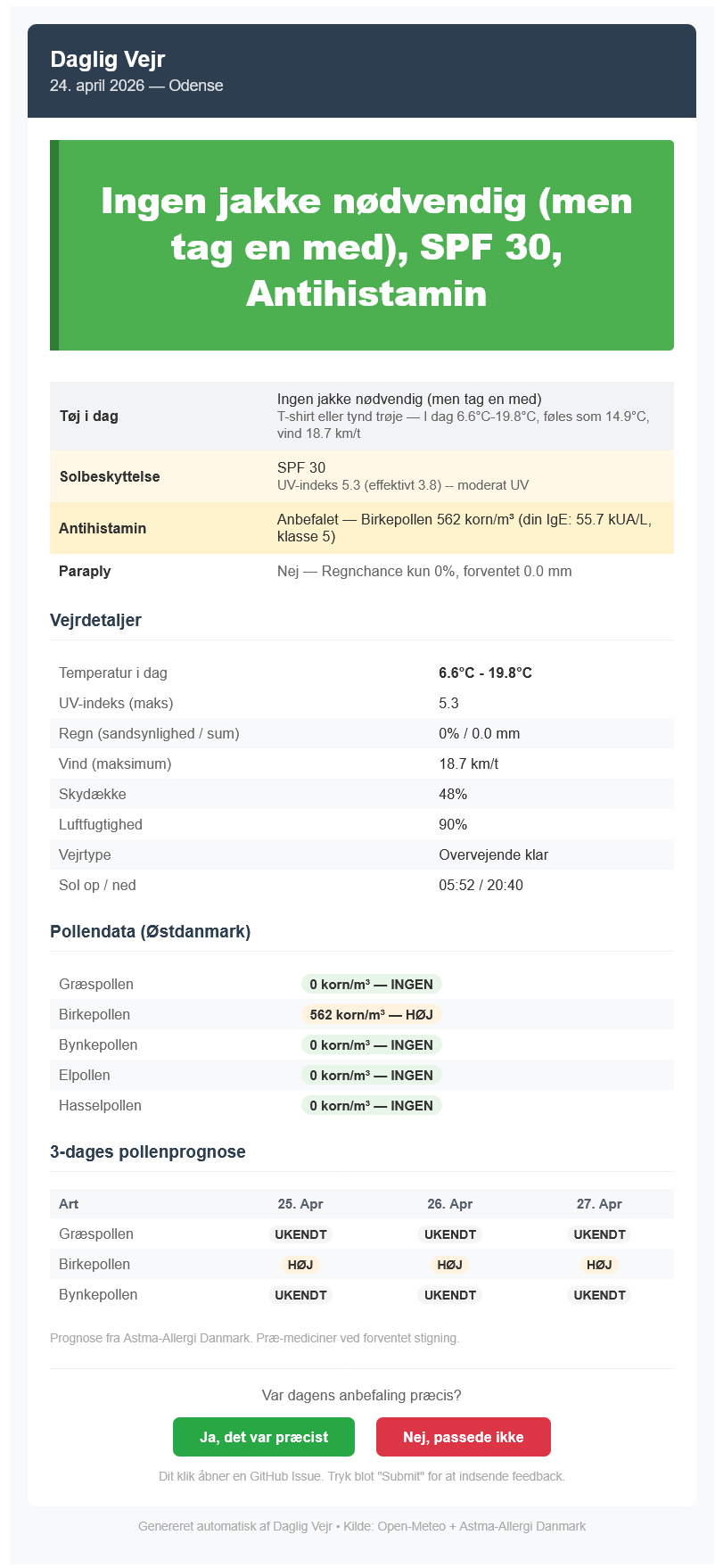
The email as it arrives each morning
Data sources
Weather comes from Open-Meteo, completely free with no API key required. It covers Odense with UV index, precipitation probability, cloud cover, wind speed, and apparent temperature. UV index matters specifically for the sunscreen recommendation and DMI's free tier doesn't expose it.
Pollen measurements come from Astma-Allergi Danmark via the internal JSON endpoint their official Dagens Pollental app uses. The response is a Firestore-format document with measurements from two Danish stations. Station 48 (Copenhagen/East Denmark) is the most representative for Odense and Funen. The endpoint also includes a 5-day forecast per species, which the email uses to suggest pre-medicating ahead of spikes.
Why not DMI for pollen? DMI doesn't expose a public pollen API. The Astma-Allergi endpoint is undocumented but stable and used by several independent integrations. When it's unreachable, or outside the April to September season, the fetcher falls back to zero values rather than crashing.
Personalised thresholds
Standard pollen advisories suggest antihistamines when grass pollen passes 30 grains/m3, a population average. With class 6 IgE sensitivity, that threshold is far too high. Blood test results from a hospital test directly set the thresholds the system uses, with grass and birch pollen triggering a recommendation well below the population-level cutoffs due to class 5 and 6 sensitivity respectively.
These values are stored as a GitHub Secret, a JSON blob injected at runtime, so the medical data never appears in the codebase or commit history. The thresholds are a starting point; the feedback loop described below is designed to refine them further over time.
Architecture
Three standalone Python scripts, each triggered by a GitHub Actions workflow. No server, no container, no persistent process.
| Script | Trigger | What it does |
|---|---|---|
weather_job.py |
Daily, 04:00 UTC | Fetches weather and pollen, applies rules, sends email, commits history.json |
feedback_job.py |
GitHub Issue opened | Parses feedback from the email links, writes it to history.json, closes the issue |
train_job.py |
Weekly, Saturday | Trains a Random Forest on labeled history, saves model and metrics back to the repo |
Daily job
At 04:00 UTC the daily workflow fetches both data sources, loads the trained ML model if one exists, applies the classification rules with any model-derived threshold adjustments, sends the email, and appends the day's record to data/history.json. That file is committed back to the repo at the end of every run, so the full history is visible in the commit graph.
Feedback loop
Each email has two links at the bottom: "Ja, det var praecist" and "Nej, passede ikke". Clicking one opens a pre-filled GitHub Issue. A second workflow triggers on issue creation, parses the title, writes the feedback into history.json, and closes the issue automatically. Start to finish it takes under thirty seconds and requires nothing beyond the click.
ML layer
A third workflow runs every Saturday. Once 20 or more labelled daily records have accumulated, it trains a Random Forest classifier on 13 features including temperature, UV index, pollen counts, season, and day of week, with the binary feedback label as the target. The model produces threshold adjustments rather than replacing the rules: it might lower the grass pollen pill threshold if the data suggests symptoms start earlier than expected. Cross-validation accuracy and feature importances are saved to data/model_metrics.json and committed alongside the model file.
Keeping the rules and the model separate was a deliberate choice. The rules give explainable outputs from day one. The model improves personalisation over time without making the system opaque, or dependent on having enough training data to function at all.
Deployment
Everything runs on GitHub Actions' free tier for public repos. The three workflows combined use well under a minute of compute per day. No infrastructure to maintain, no server costs, nothing to keep alive.
Total monthly cost: zero. Open-Meteo is free, Astma-Allergi's data is free for personal use, Gmail app passwords are free, and GitHub Actions covers this workload comfortably within the free allowance.
What I learned
The Astma-Allergi API was the most interesting part to reverse-engineer. The endpoint returns a Firestore-format document, deeply nested, with integerValue and doubleValue as separate keys rather than plain numbers. More usefully, it returns -1 for species with no measurement that day rather than omitting the key entirely. That kind of detail only shows up when you look at actual responses across a range of dates and species, not from any documentation.
The calibration side taught me something I didn't expect: writing a system whose output you act on every morning makes correctness feel very concrete. A pill recommendation on a zero-pollen day because a threshold is slightly off isn't a metric on a dashboard, it's an unnecessary antihistamine. The feedback mechanism exists to close that loop systematically.
The production discipline side was also a genuine lesson. Code that runs daily at 06:00, commits outputs to version control, processes asynchronous user input through GitHub Issues, and recovers cleanly when an upstream API returns unexpected data requires a different kind of thinking than a notebook analysis. Observability and failure modes matter in a way they simply don't when you're running something once.